POL 304: Using Data to Understand Politics and Society
Web-Scraping
Olga Chyzh [www.olgachyzh.com]
Outline
What is webscraping?
Webscraping using
rvestExamples
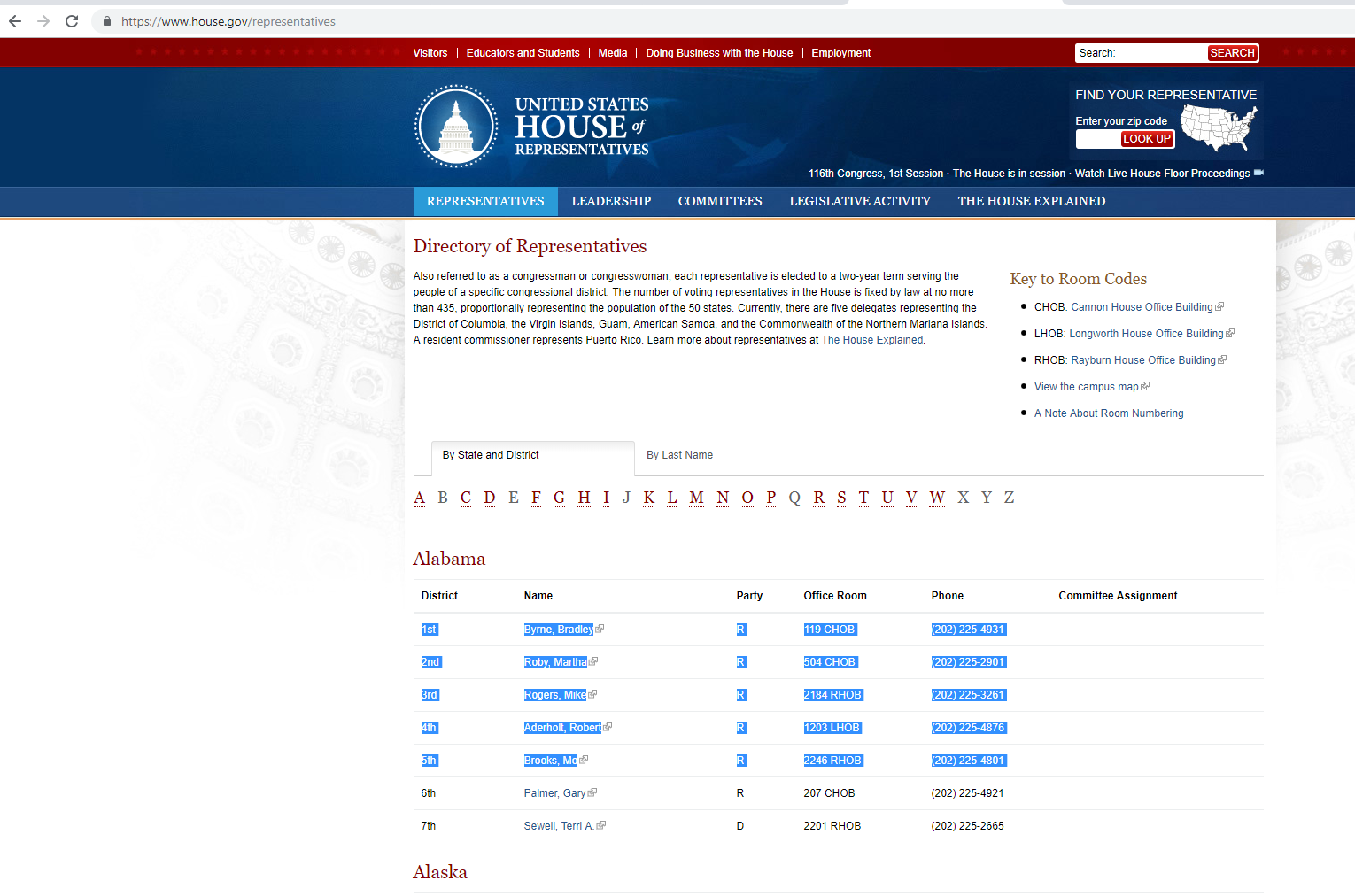
GDP form Wikipedia
2020 US election returns
Cleaning the data with
tidyverse
What is Webscraping?
Extract data from websites
Tables
Links to other websites
Text
Why Webscrape?
Because copy-paste is tedious
Because it's fast
Because you can automate it
Because it helps reduce/catch errors
Webscraping: Broad Strokes
All websites are written in
HTML(mostly)HTMLcode is messy and difficult to parse manuallyWe will use R to
- read the
HTML(or other) code - clean it up to extract the data we need
- read the
Need only a very rudimentary understanding of
HTML
Webscraping with rvest: Step-by-Step Start Guide
Install all tidyverse packages:
# check if you already have itlibrary(tidyverse)library(magrittr)library(rvest)# if not:install.packages("tidyverse")library(tidyverse) # only calls the "core" of tidyverseStep 1: What Website Are You Scraping?
# character variable containing the url you want to scrapemyurl<-"https://en.wikipedia.org/wiki/List_of_countries_by_GDP_(nominal)"Step 2: Read HTML into R
HTMLis HyperText Markup Language.Go to any website, right click, click "View Page Source" to see the HTML
library(rvest)library(tidyverse)library(magrittr)myhtml <- read_html(myurl)myhtml## {html_document}## <html class="client-nojs" lang="en" dir="ltr">## [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...## [2] <body class="skin-vector-legacy mediawiki ltr sitedir-ltr mw-hide-empty-e ...Step 3: Where in the HTML Code Are Your Data?
Need to find your data within the
myhtmlobject.In
HTML, all objects, such as tables, paragraphs, hyperlinks, and headings, are inside "tags" that are surrounded by <> symbolsExamples of tags:
<p>This is a paragraph.</p><h1>This is a heading.</h1><a>This is a link.</a><li>item in a list</li><table>This is a table.</table>
Can use Selector Gadget to find the exact location. Enter
vignette("selectorgadget")for an overview.Can also skim through the raw html code looking for possible tags.
For more on HTML, check out the W3schools' tutorial
You don't need to be an expert in HTML to webscrape with
rvest!
Step 4:
Give HTML tags into html_nodes() to extract your data of interest. Once you got the content of what you are looking for, use html_text to extract text, html_table to get a table
mytable<-html_nodes(myhtml, "table") %>% #Gets everything in the element html_table(fill=TRUE) #Convert to an R table, fill=TRUE is necessary when the website has multiple tablesmytable<-mytable %>% extract2(3) #since the website has multiple tables, we need to extract the 3rd one.#Or you can combine the operations into a pipe:mytable<-read_html(myurl) %>% html_nodes("table") %>% html_table(fill=TRUE) %>% extract2(3)Step 5: Save and Clean the Data
You may want to remove all columns except Country and GDP.
- Use
selectfromtidyverseto select these columns
- Use
You may want to delete any extra rows
- Use
sliceto select the rows you need.
- Use
You may want to clean up country names by removing any unnecessary symbols (e.g. [])
- Use
mutateandstr_extract
- Use
Finally, we need to convert GDP to a numeric variable
- Use
parse_number
- Use
Step 5: Save and Clean the Data
library(stringr)library(magrittr)mytable<-read_html(myurl) %>% html_nodes("table") %>% html_table(fill=TRUE) %>% extract2(3) %>% #our table is actually nested within a list element [[]] select(Country=1, Year=4, GDP=3) %>% slice(3:214) %>% mutate( Year=str_remove(Year, ".*\\]"), #remove everything before the ] GDP=str_remove(GDP, ".*\\]"),GDP=parse_number(GDP), Year=parse_number(Year))Your Turn (5 min)
Follow the same steps to scrape the Wikipedia table of foreign direct investments
Clean up the output the best you can. Feel free to consult the
stringrcheatsheet
Example 2
We will scrape the 2020 US Presidential Election returns for the state of Maryland
Then we will select county, and the votes for just the two major candidates, remove the total, and convert the votes to numeric values.
myurl<-"https://elections.maryland.gov/elections/2020/results/general/gen_detail_results_2020_4_BOT001-.html"pres<-read_html(myurl) %>% html_nodes("table") %>% html_table(fill=TRUE) %>% extract2(2) %>% select(County=Jurisdiction, Biden20=contains("Biden"), Trump20=contains("Trump")) %>% filter(str_detect(County, "Total", negate=TRUE)) %>% mutate(Biden20=parse_number(Biden20), Trump20=parse_number(Trump20))Your Turn (5 min)
Follow the same steps to scrape the 2016 US Presidential returns by county for the state of Maryland.
Clean up the results
Challenge Yourself
Follow the steps learned in class to scrape the names, ridings, and party of the current Ontario MPPs from https://www.ola.org/en/members/current.
Extract the links to each individual MPP website and use it to get a list of their email addresses.